Table of contents
CDN vs origin server latency
A CDN can make your site feel instantly local – or it can quietly act as an expensive pass-through that still forces shoppers to wait on a distant origin. The difference shows up first in latency, and it often decides whether a page feels snappy enough to browse (and buy) or just slightly "sticky" and slow.
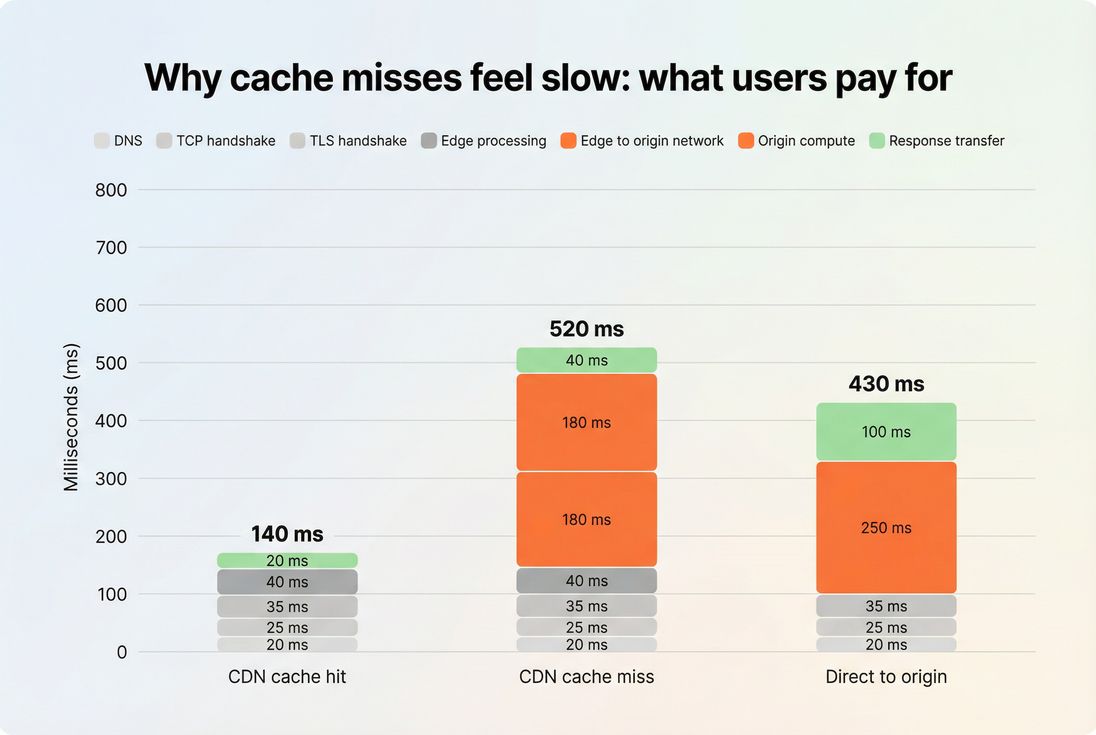
CDN vs origin server latency is the practical comparison between how long it takes a user's request to be served by a nearby CDN edge versus how long it takes to go all the way to your origin server (and back). On a cache hit, users mainly pay "edge latency." On a cache miss, users pay edge latency + origin latency + origin work – which is why misses tend to create the worst slow spikes.
This matters because latency is a major component of TTFB, and TTFB strongly influences downstream rendering milestones like FCP and LCP, especially on mobile networks with higher network latency.
What this metric really reveals
Most website owners first notice "CDN vs origin latency" when they see TTFB behaving inconsistently:
- Homepage seems fast in one region but slow in another
- Product pages are fast sometimes, slow other times
- Performance drops after a deploy, even though the CDN is "enabled"
In plain terms, this comparison answers two business questions:
- Are we actually serving users from the edge (cache hits)?
- When we don't, how expensive is the trip to origin?
The two latency paths users experience
1) CDN cache hit (best case)
The request is answered by a nearby edge node. Users mostly pay:
- DNS + connection setup (sometimes reduced by reuse)
- edge processing time
- the time to send the first byte back
2) CDN cache miss (common worst case)
The edge can't serve the content, so it forwards the request to your origin. Users pay:
- everything in a cache hit, plus
- edge-to-origin network travel (often long-haul)
- origin compute time (application + database + backend calls)
3) Direct-to-origin (usually not what you want)
Some requests bypass the CDN entirely (misconfiguration, different domain, APIs, redirects). Users pay:
- client-to-origin network distance
- origin compute time
- response transfer
The Website Owner's perspective: When you see "random" slowness, it's often not random – it's a split population of cache hits vs misses. That creates inconsistent user experience, inconsistent conversion rates, and support tickets that are hard to reproduce.
What influences the difference most
The delta between CDN-served and origin-served responses is dominated by:
- Physical distance and routing: cross-country vs cross-ocean adds real delay. See ping latency and network latency.
- Connection setup overhead: DNS lookup time, TCP handshake, TLS handshake.
- Connection reuse: if you reuse connections well, handshakes matter less. See connection reuse.
- Cache behavior: hit rate, TTL, and cache key rules. See edge caching and Cache-Control headers.
- Origin response time variability: slow database queries, cold starts, queueing, third-party dependencies. See server response time.
How website owners measure it
You can't manage what you don't measure – and CDN vs origin latency is a great example because "average TTFB" often hides the story. You need to separate requests into at least two buckets: cache hits and cache misses (and ideally also "bypassed CDN").
A practical measurement approach
Step 1: Pick representative URLs
- One HTML page (homepage or product page)
- One large static asset (hero image or CSS bundle)
- One API endpoint (if relevant)
Step 2: Measure from multiple geographies Synthetic tests are useful here because you can intentionally test "far" regions where origin distance is most punishing. (Field data is still the truth – more on that below.)
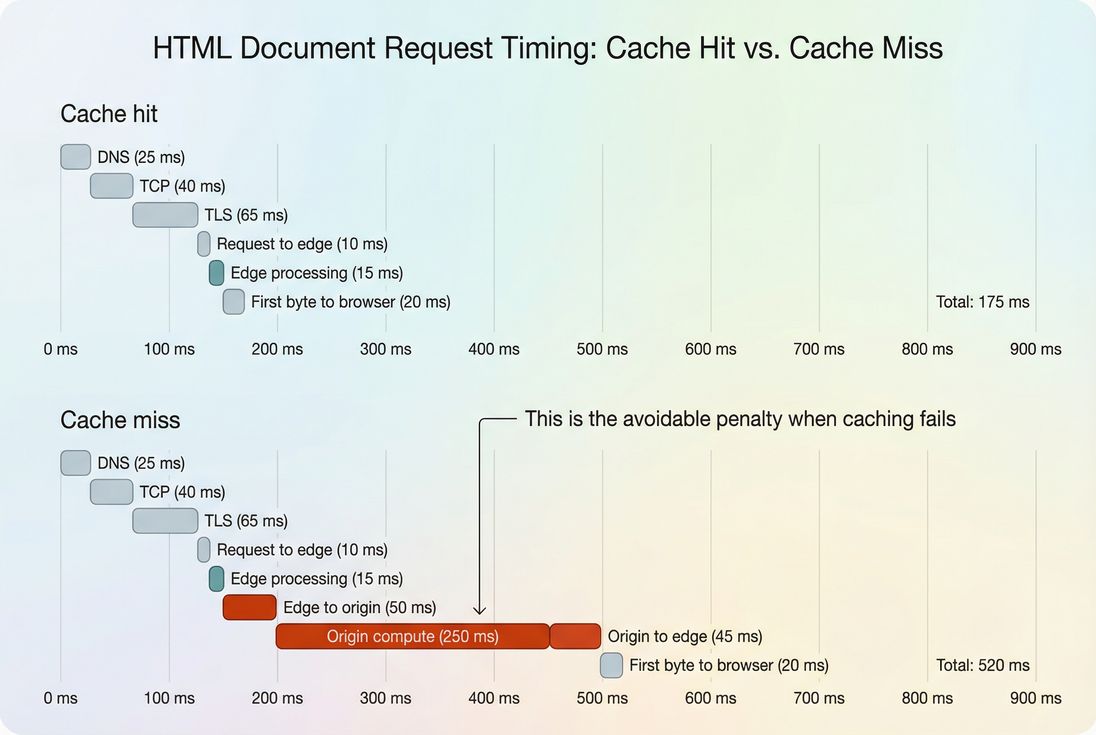
Step 3: Confirm cache status You're looking for evidence that the response was served from edge vs fetched from origin. Many CDNs expose this via response headers (for example, cache status, age, or a hit/miss marker). The exact names vary.
Step 4: Compare TTFB by cache status
- Cache-hit TTFB tells you your "edge-local" experience.
- Cache-miss TTFB reveals your "origin penalty."
If you're using PageVitals, the network request waterfall view is designed for this kind of investigation. See: /docs/features/network-request-waterfall/ and the metric docs for /docs/metrics/time-to-first-byte/ and /docs/metrics/round-trip-time/.
Lab vs field: don't confuse them
- Lab tests (synthetic) help you reproduce and isolate cache miss behavior and regional distance effects.
- Field data tells you how real users actually experience the blend of hits and misses across devices and networks.
To keep yourself honest, anchor decisions in field distributions and the 75th percentile. See field vs lab data and Measuring Web Vitals. For market-level reality checks, CrUX data can be helpful.
Benchmarks that are actually useful
Benchmarks should guide triage, not become a vanity metric. A "good" number depends on geography, network quality, and cacheability. Still, you can use practical thresholds to identify when latency is your limiting factor.
Practical targets (rule-of-thumb)
| Scenario | What you're aiming for | What's a red flag |
|---|---|---|
| CDN cache-hit TTFB (HTML or static asset) | ~100–200 ms | >300 ms consistently |
| CDN cache-miss TTFB (HTML) | stable and predictable | spikes of +300–800 ms |
| Origin compute time (server processing portion) | consistently low | highly variable across requests |
| Cross-region gap (same page) | small differences | one region 2–4× slower |
Why these matter:
- If cache-hit TTFB is high, your "edge-local" experience is already slow (routing, handshake, edge overload, misconfiguration).
- If cache-miss TTFB is high, your origin distance and/or origin work is expensive.
- If the gap between hit and miss is huge, your cache strategy is doing a lot of work when it works – but your users are punished when it doesn't.
How this ties to Core Web Vitals
Latency doesn't directly equal Core Web Vitals, but it strongly influences them:
- Higher TTFB delays the start of the critical rendering path.
- If the LCP resource can't even start downloading early, LCP will suffer.
- Slow HTML delivery can cascade into delayed CSS/JS discovery, increasing render blocking. See render-blocking resources and critical CSS.
The Website Owner's perspective: If your paid traffic lands on pages that are "usually cached but sometimes not," you're buying two different experiences. The slow cohort often overlaps with first-time visitors and new geographies – the exact people you're paying to acquire.
When it breaks (and how to spot it)
Most real-world CDN vs origin latency problems come from one of three patterns: cacheability drift, origin variability, or connection/routing regressions.
Pattern 1: cache hit rate quietly collapses
Common causes:
- Cookies or headers make responses uncacheable (or create too many variants)
- Query parameters bust cache unintentionally
- Cache TTLs reduced during a campaign or deploy
Varyheader changed (explodes cache key cardinality)- Personalized HTML served everywhere (no microcaching)
What it looks like:
- Average TTFB increases slightly, but the 75th/95th percentile jumps a lot
- Specific pages (product detail) get worse, not the whole site
- Some regions get hammered (farther from origin)
Fix direction:
- Start with Cache-Control headers and Cache TTL.
- Use edge caching for assets and selectively for HTML where safe.
- Reduce variant explosion (tighten
Vary, normalize query strings).
Pattern 2: origin compute gets spiky
Common causes:
- Database slowdowns, lock contention, missing indexes
- Cold starts (serverless or autoscaling)
- Third-party API dependencies
- Deploy introduces slower server-side rendering
- Increased origin CPU due to compression done inefficiently (rare, but possible)
What it looks like:
- Cache-miss TTFB worsens
- P95 gets much worse than P50
- Spikes align with traffic peaks or deploy times
Fix direction:
- Treat it as an origin performance issue first: server response time.
- Consider caching layers (application-level, database, or microcaching at edge).
- Ensure compression is configured properly (often "free" wins): Brotli compression or Gzip compression.
Pattern 3: connection setup or routing regresses
Common causes:
- Missing keep-alive/connection reuse
- TLS misconfiguration or poor session reuse
- DNS issues or slow resolvers
- HTTP protocol downgrade (loss of multiplexing benefits)
What it looks like:
- Even cache-hit requests have high TTFB
- DNS/TCP/TLS phases are large in waterfalls
- Performance changes without code changes
Fix direction:
- Improve connection reuse.
- Evaluate HTTP/2 performance and HTTP/3 performance support.
- Use preconnect and DNS prefetch where it makes sense (carefully – don't spam).
Fixes that move the needle
The best improvements come from reducing the number of times users pay for origin, and reducing the cost when they do.
1) Maximize safe edge hits
Start with what you can confidently cache:
- Static assets: JS, CSS, images, fonts
Use strong caching + versioned filenames. Pair with browser caching so repeat views are instant. - HTML (selectively): landing pages, category pages, product pages
Use shorter TTLs and careful cache keys.
Key implementation ideas (conceptually):
- Cache public pages; bypass cache for cart/checkout/account.
- Keep cache keys stable (avoid unnecessary query params).
- Don't let a single cookie force "no-store" on everything.
Supporting concepts:
The Website Owner's perspective: You don't need to cache everything to see business impact. If your top landing pages and top product pages become reliably "edge-fast," paid traffic becomes more efficient because fewer clicks are wasted on slow first impressions.
2) Reduce the miss penalty (make origin cheaper)
Even with great caching, you'll have misses:
- first-time visitors
- cache evictions
- personalized requests
- inventory/price changes
So you want origin to be:
- fast (low compute time)
- stable (few spikes)
- close enough (reasonable network distance)
Practical levers:
- Optimize server-side work: server response time.
- Avoid needless payload bloat (especially HTML): compression + trimming. See asset minification.
- Make expensive endpoints cache-friendly (microcaching for 1–10 seconds can smooth peak load without serving stale content for long).
3) Keep the rendering pipeline from compounding latency
Latency hurts most when it delays the browser from discovering critical resources.
Common compounding issues:
- HTML arrives late, and CSS/JS are discovered late
- render-blocking CSS delays first paint
- JS blocks the main thread after download
Fix direction (especially for LCP improvements):
4) Make it operational: alerts and budgets
Latency regressions often arrive with:
- a marketing script
- a personalization change
- a header change that breaks caching
- a backend release
Treat CDN vs origin latency as an operational metric:
- Set a performance budget around TTFB and cache-miss penalty.
- Track p75/p95, not just averages.
If you're implementing budgets in PageVitals, start here: /docs/features/budgets/. For broader budgeting strategy, see performance budgets.
A quick way to interpret changes
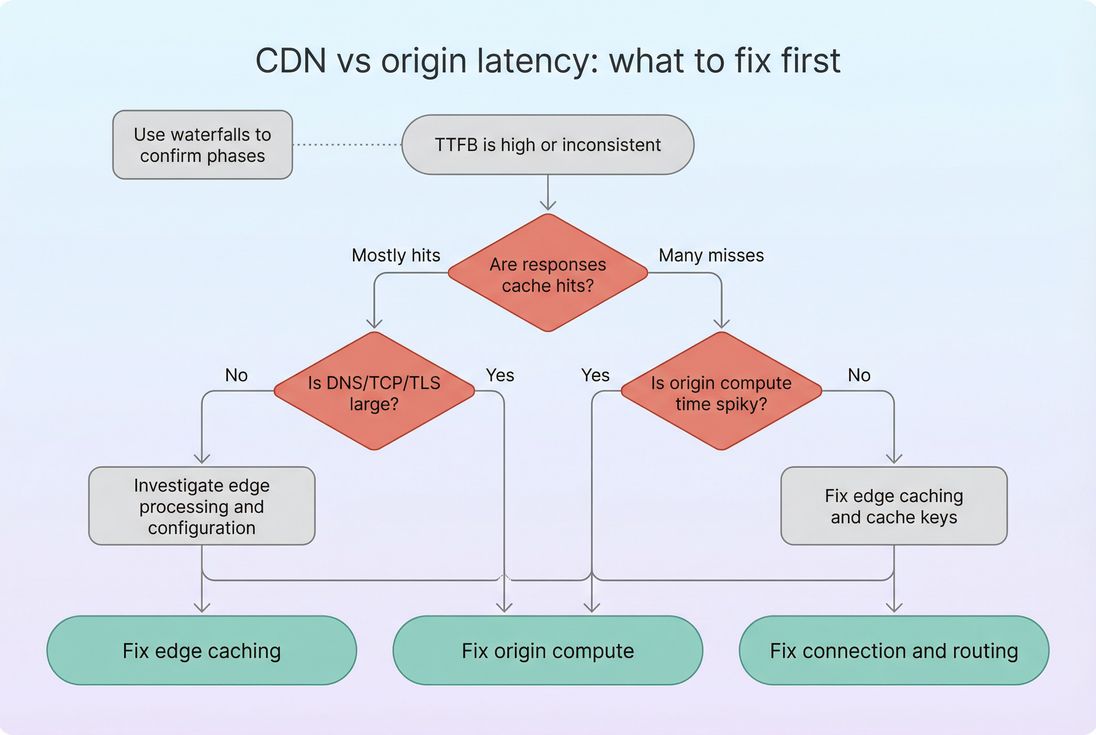
When you see a change in "CDN vs origin latency," interpret it by asking what must have changed:
Did cache-hit TTFB change?
Likely connection/routing/edge configuration. Look at DNS/TCP/TLS and connection reuse.Did cache-miss TTFB change but cache-hit stayed flat?
Likely origin compute change or origin distance/routing. Correlate with deploys, backend incidents, database metrics.Did the gap between hit and miss widen?
Origin became more expensive or cache misses increased. Verify cache status distribution.Did only certain pages regress?
Likely cacheability rules (cookies,Vary, query strings) or a slow backend path for those templates.
Checklist for busy teams
- Confirm whether your slow cohort is cache misses (not "a slow CDN").
- Measure from multiple regions; compare hit vs miss TTFB.
- Tighten cache rules using Cache-Control headers and sane Cache TTL.
- Fix origin spikiness (DB, backend calls, SSR) using server response time.
- Reduce handshake overhead with connection reuse and selective preconnect.
- Tie the work to outcomes: improved TTFB typically lifts LCP on real devices – especially on mobile.
If you want, share (1) a few representative URLs, (2) your primary traffic geographies, and (3) whether HTML is currently cached at the edge. I can suggest which measurement split (hit/miss/bypass) will give you the fastest root cause.
Frequently asked questions
For cacheable content, a CDN cache hit should usually cut perceived latency dramatically because the request stays local to a nearby edge. If your origin is cross-country or cross-ocean, it's common to save 100–400 ms on TTFB. If you're only saving 20–50 ms, you may be missing cache or routing benefits.
A fast CDN only helps on cache hits. If HTML is uncacheable or you have low hit rates due to cookies, query strings, or short TTLs, the CDN becomes a proxy and your users still pay origin latency. Check cache status headers and compare cache-hit vs cache-miss TTFB from multiple regions.
As a practical target, aim for edge TTFB under about 200 ms for cache hits on typical pages, and keep origin response time consistently low so cache misses don't spike. Origin latency should be stable across deploys. Your real targets should be set at the 75th percentile using field data, not best-case lab tests.
Often yes, but selectively. Cache category pages, product pages, and landing pages with careful variation rules, while keeping cart, checkout, and account pages dynamic. Short-lived edge caching (microcaching) can still reduce origin load and smooth traffic spikes. The key is controlling personalization with Vary logic and cache keys.
Move or regionalize origins when you have high global traffic and a meaningful share of requests are cache misses or dynamic endpoints that can't be cached at the edge. If you see persistent region-based gaps in TTFB and LCP, multi-region origin or closer compute can be a direct conversion lever – especially on mobile.
Want to take PageVitals for a spin?
Page speed monitoring and alerting for your website. Get daily Lighthouse reports for all your pages. No installation needed.
Start my free trial